
Pandas é uma biblioteca para ser utilizada em python para mexer com manipulação de dados.
Vou inserir abaixo materiais da própria documentação (cliquei aqui para acessar a documentação), alguns livros de datascience, chat gpt (óbvio) e alguns pontos de vista meu mesmo. :) Vou utilizar o VS code como IDE e preciso instalar python e depois no terminal do vs code, clico na guia terminal, novo terminal, e digito: pip install pandas e aguardo a instalação.
Para importar a biblioteca pandas para o seu projeto digitamos import pandas as pd
De acordo com a documentação para seguir as boas práticas o alias acordado pela comunidade a forma abreviada de chamar pandas será: pd.
Perceba que a palavra pandas está apresentando um erro, isso ocorre pois ainda não fizemos a instalação da biblioteca e por este motivo, ela não esta sendo reconhecida.

Instalação da biblioteca pandas concluída:

DataFrame
É uma estrutura de dados bidimensional que pode armazenar dados de diferentes tipos (incluindo caracteres, inteiros, valores de ponto flutuante, dados categóricos e mais) em colunas. É semelhante a uma planilha, uma tabela SQL.
Série
É um objeto unidimensional que pode conter qualquer tipo de dado (números, strings, dados, etc.).
Funciona como um array do NumPy, mas com um índice associado.
Pode existir sozinho, sem estar dentro de um DataFrame

Lendo arquivo Excel com pandas
Para ler arquivos Excel precisaremos instalar a biblioteca openpyxl pelo terminal (pip install openpyxl), da mesma forma que instalamos pandas.
🌕 Exibir as 5 primeiras e 5 últimas linhas
import pandas as pd
# Caminho de onde esta o arquivo que queremos fazer a leitura
file_path = r"C:\Users\amand\Downloads\tabagp.xlsx"
# Lendo a planilha Excel
df = pd.read_excel(file_path)
# Exibir as primeiras 5 linhas
print("🔹 Primeiras 5 linhas:")
print(df.head())
# Exibir as últimas 5 linhas
print("\n🔹 Últimas 5 linhas:")
print(df.tail())Saída com o exemplo dos dados existentes na minha planilha:

🌕 Exibir todos os dados
import pandas as pd
# Configuração para exibir todas as linhas e colunas
pd.set_option("display.max_rows", None) # Exibir todas as linhas
pd.set_option("display.max_columns", None) # Exibir todas as colunas
# Caminho do arquivo
file_path = r"C:\Users\amand\Downloads\tabagp.xlsx"
# Lendo a planilha Excel
df = pd.read_excel(file_path)
# Exibir o DataFrame completo
print(df)Lendo arquivo csv com pandas
🌕 Exibir todos os dados
import pandas as pd
# Configuração para exibir todas as linhas e colunas
pd.set_option("display.max_rows", None) # Exibir todas as linhas
pd.set_option("display.max_columns", None) # Exibir todas as colunas
# Caminho completo do arquivo CSV
file_path = r"C:\Users\amand\Downloads\tabagp.csv"
# Lendo o arquivo CSV
df = pd.read_csv(file_path, sep=",", encoding="utf-8")
# Altere o separador se necessário
# Exibir o DataFrame completo
print(df)Lendo arquivo parquet com pandas
🌕 Exibir todos os dados
import pandas as pd
# Configuração para exibir todas as linhas e colunas
pd.set_option("display.max_rows", None) # Exibir todas as linhas
pd.set_option("display.max_columns", None) # Exibir todas as colunas
# Caminho completo do arquivo Parquet
file_path = r"C:\Users\amand\Downloads\tabagp.parquet"
# Lendo o arquivo Parquet
df = pd.read_parquet(file_path)
# Exibir o DataFrame completo
print(df)🌕 Exibir as 10 primeiras linhas
print(df.sample(10))
🌕 Exibir as 5 primeiras e 5 últimas linhas
import pandas as pd
# Caminho completo do arquivo Parquet
file_path = r"C:\Users\amand\Downloads\tabagp.parquet"
# Lendo o arquivo Parquet
df = pd.read_parquet(file_path)
# Exibir as primeiras 5 linhas
print("🔹 Primeiras 5 linhas:")
print(df.head())
# Exibir as últimas 5 linhas
print("\n🔹 Últimas 5 linhas:")
print(df.tail())Formato | Função dos Pandas | Observação |
CSV ( .csv) | pd.read_csv() | Arquivos separados por vírgula (ou outro delimitador) |
Excel ( .xlsx, .xls) | pd.read_excel() | pip install xlrd openpyxl |
Parquet ( .parquet) | pd.read_parquet() | Ótimo para grandes volumes de dados |
JSON ( .json) | pd.read_json() | Para dados estruturados em formato JSON |
SQL (banco de dados) | pd.read_sql() | Solicitar conexão com banco de dados (sqlite3, SQLAlchemy) |
HTML (tabelas da web) | pd.read_html() | pip install lxml html5lib beautifulsoup4 |
PDF ( .pdf) | Usando pdfplumber, camelotouPyMuPDF | Necessita de bibliotecas externas para extrair texto/tabelas |
word ( .docx) | Usandopython-docx | Necessita de python-docxler documentos Word |
Obter alguns dados do dataframe
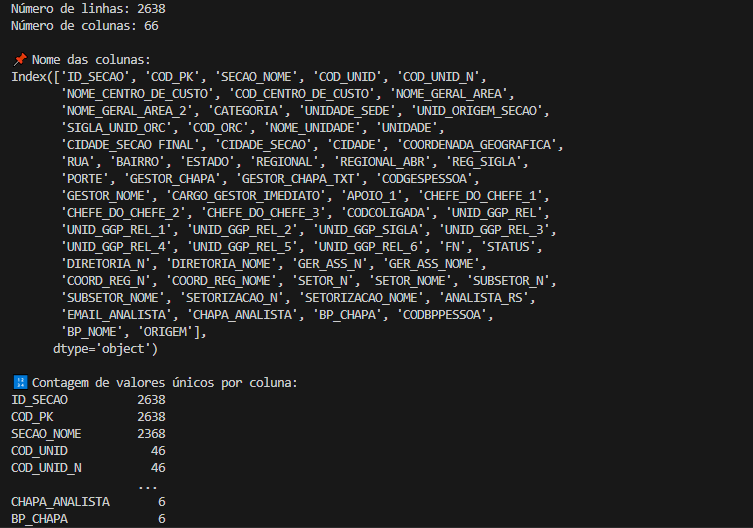
🌕 Obter quantidade de linhas e colunas
🌕 Exibir nome das colunas
🌕 Contagem de valores únicos
import pandas as pd
file_path = r"C:\Users\amand\Downloads\tabagp.xlsx"
df = pd.read_excel(file_path)
# Número de linhas e colunas
num_linhas, num_colunas = df.shape
print(f"Número de linhas: {num_linhas}")
print(f"Número de colunas: {num_colunas}")
# Exibir os nomes das colunas
print("\n📌 Nome das colunas:")
print(df.columns)
# Contagem de valores únicos por coluna
print("\n🔢 Contagem de valores únicos por coluna:")
print(df.nunique())
Exemplo de saída:
🌕 Identificar possibilidade de chave primária
import pandas as pd
# Caminho do arquivo
file_path = r"C:\Users\amand\Downloads\tabagp.xlsx"
# Lendo o arquivo Excel
df = pd.read_excel(file_path)
# Verificando colunas candidatas a chave primária
for coluna in df.columns:
valores_unicos = df[coluna].nunique()
total_linhas = len(df)
valores_nulos = df[coluna].isnull().sum()
if valores_unicos == total_linhas and valores_nulos == 0:
print(f"✅ A coluna '{coluna}' pode ser uma chave primária (valores únicos e sem nulos).")
else:
print(f"❌ A coluna '{coluna}' NÃO é uma chave primária (valores únicos: {valores_unicos}, total linhas: {total_linhas}, nulos: {valores_nulos}).")Exemplo de saída:
