Repositório de dados é um local onde informações e dados são armazenados, organizados e gerenciados para permitir seu acesso e uso. Ele pode assumir diferentes formas e propósitos, dependendo da natureza dos dados, do nível de organização e do objetivo de sua utilização. Em um contexto geral, os repositórios de dados são usados para centralizar, organizar e facilitar o acesso a informações de uma organização, aplicativo ou sistema.
Características gerais de um repositório de dados:
Armazenamento estruturado ou não estruturado: Repositórios podem armazenar dados de maneira organizada (como em tabelas e bancos de dados relacionais) ou em formatos brutos e variados (documentos, arquivos, vídeos, etc.).
Acesso e consulta: Permitem que os usuários ou sistemas acessem, consultem e extraíam informações para análises, relatórios ou aplicações operacionais.
Segurança e governança: Implementam políticas de controle de acesso, backup, e recuperação, além de garantir que os dados sejam gerenciados de forma segura e em conformidade com normas e regulamentos.
Escalabilidade: Repositórios podem crescer em termos de volume de dados armazenados, desde pequenos bancos de dados até grandes infraestruturas como Data Lakes.
Integração: São projetados para integrar dados provenientes de várias fontes, como sistemas transacionais, sensores IoT, logs de servidores, etc.
➡ Data Warehouse relacional (RDW) (surgiu em 1984)
DW relacional é baseado no modelo relacional, onde os dados são organizados em tabelas (criando relações) e estas tabelas são compostas de linhas e colunas e cada linha representa uma entidade (como um cliente ou produto) e cada coluna representa um atributo dessa entidade *como nome, preço ou quantidade).

Armazena dados estruturados que foram transformados e organizados para análises e relatórios.
Usar um RDW torna mais fácil criar qualquer tipo de solução em BI, sem ser necessário criar uma lógica complexa para a extração de dados de vários sistemas de origens.
Uso Comum: Business Intelligence (BI), relatórios operacionais. Armazenamento relacional.
Exemplos: Snowflake, Amazon Redshift, Google BigQuery, SQL Server.
Vale ressaltar aqui que nem todos os data warehouses são baseados no modelo relacional como por exemplo o NoSQL, porem, o modelo relacional é mais adequado para dados estruturados. Um RDW age como um repositório central para muitas áreas e contém a SVOT (versão única da verdade).
Os métodos de extração dos sistemas de origem para o RDW podem ser:
Extração total
Extração incremental
e independente se é extração total ou incremental, as duas maneiras de extrair os dados são de forma:
Online
Conexão direta com o sistema de origem para acessar as tabelas de origem ou se conectar com um sistema intermediário que armazena as alterações feitas nos dados de maneira pré-configurada (Ex.: Logs de transações ou tabela de alterações)
Offline
O Acesso direto ao sistema de origem nem sempre esta disponível e os dados ficam em um estado de espera, fora do sistema de origem e são criados por uma rotina de extração originada fora deste, como por exemplo, um mainframe executa uma rotina de extração em uma tabela e deposita os dados em uma pasta em um sistema de arquivos). Geralmente os dados são inseridos em um formato genérico como CSV ou JSON.
Algumas vantagens em utilizar o RDW
💜 Reduzir o estresse no sistema de produção
💜 Otimizar o acesso a leitura
💜 Integrar várias fontes de dados
💜 Gerar relatórios de histórico precisos
💜Reestruturar e renomear tabelas
💜 Proteger contra upgrades de aplicações
💜 Reduzir as preocupações com a segurança
💜 Manter dados de histórico
💜 MDM (master data management) remover registros duplicados
💜 Melhorar a qualidade dos dados preenchendo lacunas nos sistemas de origem.
💜 Eliminar o envolvimento da área de TI na criação de um relatório
Algumas desvantagens em utilizar o RDW
⚠ Complexidade ⚠ Custo alto ⚠ Desafios de integração de dados ⚠ Transformação de dados demorada ⚠ Latência dos dados (pode ser mais lento) ⚠ Janela de manutenção ⚠ Flexibilidade limitada ⚠ preocupação com segurança e privacidade
➡ Data Mart (surgiu na década de 80)

Um subconjunto de um Data Warehouse focado em uma área específica de negócios (por exemplo, finanças, marketing).
Uso Comum: Relatórios de uma área de negócio específica, performance aprimorada ao acessar dados de um domínio restrito.
Exemplos: Data marts podem ser implementados em ferramentas como SQL Server, Oracle ou outros sistemas de Data Warehouse. Em resumo, podemos considerar o data mart um repositório de dados dedicado para atender áreas específicas.
➡ Data Lake (surgiu em 2010)

Armazena grandes volumes de dados brutos em formatos nativos (dado bruto), sendo o dado estruturados (relacional), semiestruturados (CSV, logs, XML ou JSON), não estruturados (E-mails, documentos e PDFs) ou dados binários (como imagens, vídeos e áudios) ou seja, os dados podem passar de seu sistema de origem para o data lake sem serem transformados para outro formato.
O data lake é uma maneira barata de armazenar de forma ilimitada os dados, pois ao contrário do que ocorre em armazenamentos locais, os provedores de nuvem têm armazenamento ilimitado.
Usam o armazenamento por objetos, em que os dados não precisam estar estruturados (com no banco de dados relacional) em linhas e colunas.
Ao contrário de um DW, um data lake usa o schema-on-read (esquema durante a leitura), que significa que não é necessário fazer nenhum trabalho antecipado para a inserção de dados no data lake, basta copiar os arquivos.
Uso Comum: Big Data, machine learning, análises exploratórias.
Exemplos: Hadoop, AWS S3, Azure Data Lake.

Geralmente os dados da camada bruta do data lake em conformidade são convertidos para o formato .parquet para ter uma padronização dos dados, utiliza-se também csv e json.
Algumas vantagens em utilizar data lakes
💜 Estrutura organizacional e propriedade
💜 Conformidade, governança e segurança
💜 Assinatura em nuvem, limites de serviço e políticas
💜 Desempenho, disponibilidade e recuperação de desastre
💜 Retenção de dados e gerenciamento de ambientes
Algumas desvantagens em utilizar data lake
⚠ Complexidade
⚠ Múltiplos data lakes aumentam o custo da infraestrutura e gerenciamento
Algumas diferenças entre data lake e DW
Os data lakes quando surgiram tinham a promessa de resolver todos os problemas de um DW tais como: Alto custo, escalabilidade limitada, desempenho, sobrecarga de preparação dos dados, suporte limitado e o data lake veio com a proposta de usar uma única tecnologia para resolver tudo. Porem, para consultar data lakes era necessário um conjunto de habilidades pessoais bem avançado, eram soluções complexas e difíceis e o data lake acabava sendo mais caros devido ao custo de hardware e suporte.
Os data lakes não tinham alguns recursos que as pessoas gostavam como por exemplo suporte a transações, imposição do esquema e trilhas de auditoria.

➡ Data Warehouse moderno (MDW) (surgiu em 2011)
Em 2011 muitas empresas começaram a colocar lado a lado o DW e Data Lake para aproveitar benefícios de ambos, criando então o MDW (data warehouse moderno), ou seja, o DW moderno refere-se ao uso destas duas tecnologias.

O MDW representa o "melhor" dos dois mundos (Data lake e Data warehouse). O data çake é para o staging e a preparação dos dados (os cientistas de dados utilizam para criar modelos de machine learning) e as empresas geram consultas e relatórios com o DW, garantindo a disponibilização, segurança e conformidade.
➡ Data Fabric (surgiu em 2016)
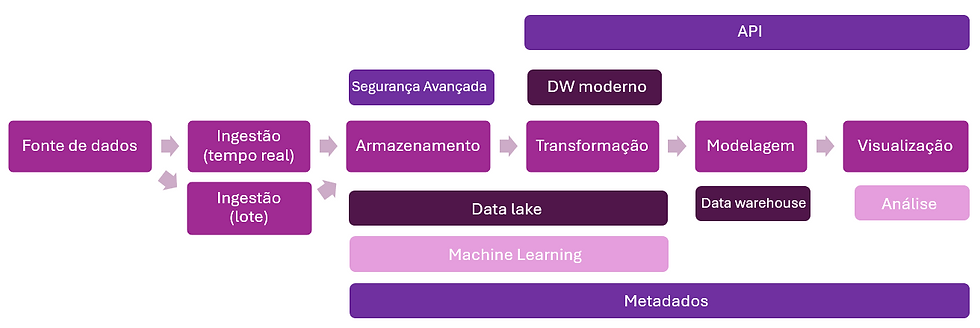
Uma arquitetura e conjunto de serviços que fornecem integração e gerenciamento de dados de maneira automatizada e inteligente em ambientes distribuídos. Podemos considerar o Data Fabric como uma evolução do MDW (data warehouse moderno), um grande framework que pode interagir com qualquer tipo de dado.
Uso Comum: Integração de dados entre nuvens públicas e privadas, sistemas on-premise e dados distribuídos.
Exemplos: Soluções baseadas em IA e automação, como IBM Cloud Pak for Data.
➡ Data Lakehouse (surgiu em 2020)

O temo data lakehouse é uma combinação de data lake e data warehouse, com a diferença do data lake para o data lakehouse é a camada adicional chamada Delta Lake que é executado acima de um data lake existente e o faz funcionar de maneira semelhante a um banco de dados relacional.
➡ Data Mesh (surgiu em 2019)
Uma abordagem descentralizada onde as equipes responsáveis pelos dados (domínios) têm autonomia para controlar seus próprios dados, com governança e padrões consistentes.
Data mesh é um conceito e não uma tecnologia. Cada domínio tem de determinar que tecnologia (data warehouse moderno, data lakehouse ou data fabric) para criar sua parte do data mesh.
O desafio que as empresas têm na centralização é o objetivo do data mesh, em resolver estes desafios, como propriedade dos dados, qualidade dos dados e o dimensionamento organizacional/técnico.
Uso Comum: Promover escalabilidade e governança em arquiteturas de dados distribuídas, especialmente em grandes organizações.
Exemplos: Arquitetura conceitual, geralmente implementada usando tecnologias como microserviços e data lakes/dwh.
➡ Operational Data Store (ODS)
Um repositório de dados operacionais usados para integrar dados de diferentes fontes em tempo real ou quase real.
Uso Comum: Integração de dados em tempo real, suporte a processos operacionais, não é usado para relatórios analíticos de longo prazo.
Exemplos: ODS pode ser implementado em sistemas como SQL Server ou ferramentas específicas de integração de dados.
➡ Data Hub
É um sistema centralizado de armazenamento e gerenciamento de dados que ajuda a empresa a coletar, integrar, armazenar, organizar e compartilhar dados de várias fontes e fornece acesso fácil a ferramentas analíticas, de geração de relatórios e tomadas de decisões Serve como um ponto centralizado de integração e distribuição de dados, sem a intenção de transformá-los ou armazená-los de forma centralizada.
Uso Comum: Integração de dados em diferentes plataformas, permitindo que múltiplos sistemas compartilhem informações.
Exemplos: IBM Data Hub, Talend Data Hub.
➡ Enterprise Data Warehouse (EDW)
Um Data Warehouse centralizado que armazena dados de toda a organização para ser usado por vários departamentos e funções.
Uso Comum: Relatórios corporativos e análise de dados de toda a empresa, integrações interdepartamentais.
Exemplos: Oracle Exadata, Teradata.
➡ NoSQL Databases
Sistemas de banco de dados que armazenam dados não estruturados ou semiestruturados, como documentos, gráficos, ou pares chave-valor.
Uso Comum: Aplicações que necessitam de alta escalabilidade e flexibilidade de dados (por exemplo, redes sociais, IoT).
Exemplos: MongoDB, Cassandra, Redis, Couchbase.
➡ Cloud Storage/Blob Storage
Armazenamento em nuvem para grandes volumes de dados, geralmente usado para armazenar arquivos, objetos ou blobs.
Uso Comum: Armazenamento de arquivos de mídia, logs, backups, e grandes datasets.
Exemplos: AWS S3, Google Cloud Storage, Azure Blob Storage.
➡ Graph Databases
Um tipo de banco de dados NoSQL otimizado para armazenar e navegar por dados inter-relacionados, como grafos de redes sociais ou mapas.
Uso Comum: Análises de redes sociais, recomendações, modelagem de relações complexas.
Exemplos: Neo4j, Amazon Neptune, OrientDB.
➡ Data Stream Platforms
Plataformas de dados otimizadas para processar e analisar dados em tempo real.
Uso Comum: Processamento de dados em tempo real, como logs de servidores, sensores IoT ou transações financeiras.
Exemplos: Apache Kafka, AWS Kinesis, Azure Event Hubs.
➡ Object Storage
Um sistema de armazenamento para grandes volumes de dados não estruturados, onde os dados são armazenados como objetos.
Uso Comum: Armazenamento de arquivos multimídia, backups e grandes datasets.
Exemplos: Amazon S3, MinIO, Google Cloud Storage.
➡ File System (NAS/SAN)
Armazenamento de arquivos usando servidores de armazenamento conectados a uma rede (Network Attached Storage - NAS) ou sistemas de armazenamento de área de rede (Storage Area Network - SAN).
Uso Comum: Armazenamento e compartilhamento de arquivos em ambientes corporativos ou pessoais.
Exemplos: NetApp NAS, Dell EMC SAN.
➡ In-Memory Databases
Armazena dados na memória principal (RAM) em vez de discos tradicionais, otimizando para leitura e gravação extremamente rápidas.
Uso Comum: Aplicações que requerem acesso em tempo real a grandes volumes de dados.
Exemplos: Redis, SAP HANA, Memcached.